Transfer Learning
Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, Qing He: A Comprehensive Survey on Transfer Learning. Proceedings of IEEE, 2020.
-
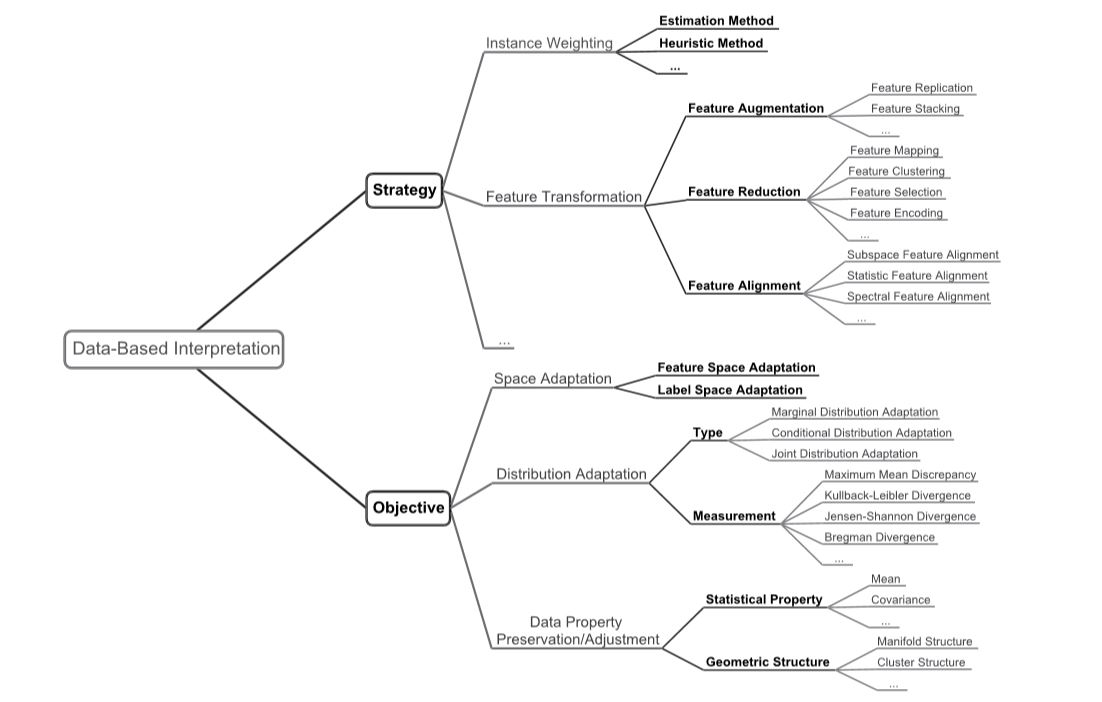
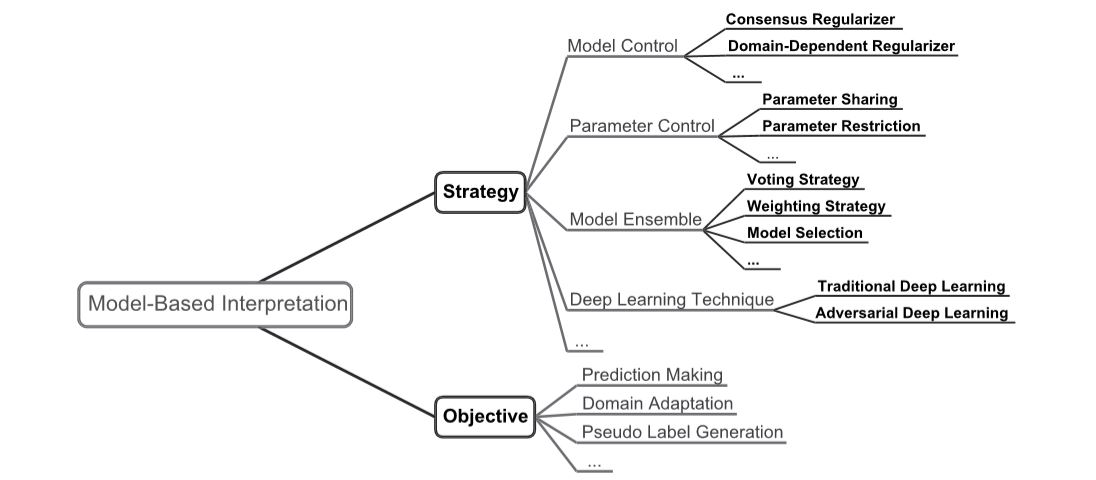
Transfer learning aims at improving the performance of target learners on target domains by transferring the knowledge contained in different but related source domains. In this way, the dependence on a large number of target-domain data can be reduced for constructing target learners. Due to the wide application prospects, transfer learning has become a popular and promising area in machine learning. Although there are already some valuable and impressive surveys on transfer learning, these surveys introduce approaches in a relatively isolated way and lack the recent advances in transfer learning. Due to the rapid expansion of the transfer learning area, it is both necessary and challenging to comprehensively review the relevant studies. This survey attempts to connect and systematize the existing transfer learning research studies, as well as to summarize and interpret the mechanisms and the strategies of transfer learning in a comprehensive way, which may help readers have a better understanding of the current research status and ideas. Unlike previous surveys, this survey article reviews more than 40 representative transfer learning approaches, especially homogeneous transfer learning approaches, from the perspectives of data and model. The applications of transfer learning are also briefly introduced. In order to show the
performance of different transfer learning models, over 20 representative transfer learning models are used for experiments. The models are performed on three different data sets, that is, Amazon Reviews, Reuters-21578, and Office-31, and the experimental results demonstrate the importance of selecting appropriate transfer learning models for different applications in practice.
|
|
|
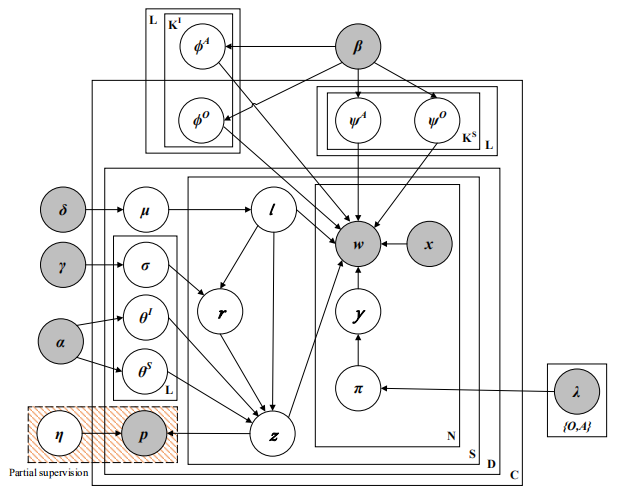
Deqing Wang, Baoyu Jing, Chenwei Lu, Junjie Wu, Guannan Liu, Chenguang Du, Fuzhen Zhuang*: Coarse Alignment of Topic and Sentiment: A Unified Model for Cross-Lingual Sentiment Classification. IEEE Transactions on Neural Networks and Learning Systems, 2020.
 |
-
Cross-lingual sentiment classification (CLSC) aims
to leverage rich-labeled resources in the source language to
improve prediction models of a resource-scarce domain in the
target language. Existing feature representation learning based
approaches try to minimize the difference of latent features
between different domains by exact alignment, which is achieved
by either one-to-one topic alignment or matrix projection. Exact
alignment, however, restricts the representation flexibility, and
further degrades model performances on cross-lingual sentiment
classification tasks if the distribution difference between two
language domains is large. On the other hand, most previous
studies proposed document-level models or ignored sentiment
polarities of topics that might lead to insufficient learning of
latent features. To solve the above problems, we propose a coarse
alignment mechanism to enhance model’s representation by a
group-to-group topic alignment into an aspect-level fine-grained
model. First, we propose an unsupervised aspect, opinion and
sentiment unification model (AOS), which tri-models aspects,
opinions and sentiments of reviews from different domains
and helps capture more accurate latent feature representation
by a coarse alignment mechanism. To further boost AOS, we
propose ps-AOS, a partial supervised AOS model, in which
labeled source language data help minimize the difference of
feature representations between two language domains with the
help of logistics regression. Last, an Expectation-Maximization
framework with Gibbs sampling is then proposed to optimize our
model. Extensive experiments on various multilingual product
review data sets show that ps-AOS significantly outperforms
various kinds of state-of-the-art baselines.
|
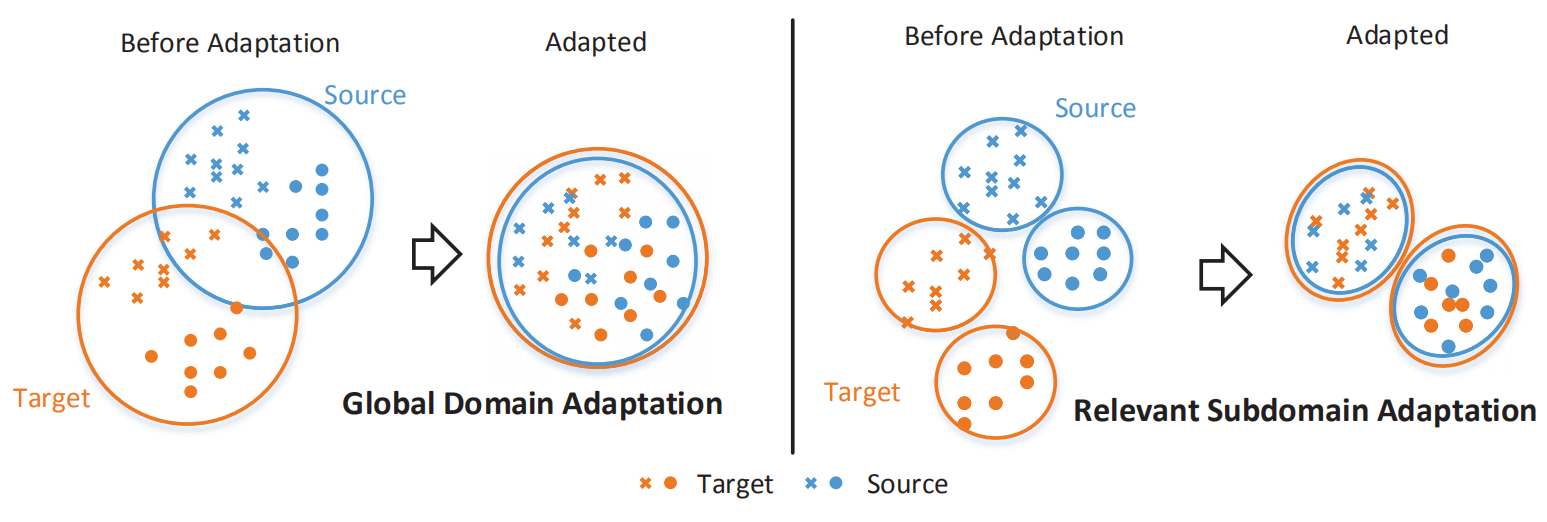
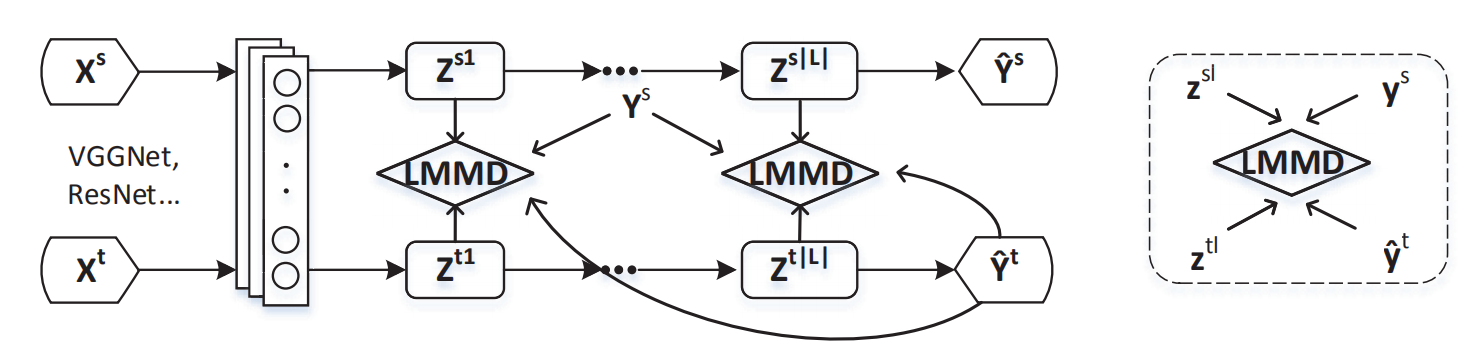
Yongchun Zhu, Fuzhen Zhuang*, Jindong Wang, Guolin Ke, Jingwu Chen, Jiang Bian, Hui Xiong and Qing He: Deep Subdomain Adaptation Network for Image Classification. IEEE Transactions on Neural Networks and Learning Systems 2020.
For a target task where labeled data is unavailable, domain adaptation can transfer a learner from a different source domain. Previous deep domain adaptation methods mainly learn a global domain shift, i.e., align the global source and target distributions without considering the relationships between two subdomains within the same category of different domains, leading to unsatisfying transfer learning performance without capturing the fine-grained information.
Recently, more and more researchers pay attention to Subdomain Adaptation which focuses on accurately aligning the distributions of the relevant subdomains. However, most of them are adversarial methods which contain several loss functions and converge slowly. Based on this, we present Deep Subdomain Adaptation Network (DSAN) which learns a transfer network by aligning the relevant subdomain distributions of domain-specific layer activations across different domains based on a local maximum mean discrepancy (LMMD). Our DSAN is very simple but effective which does not need adversarial training and converges fast. The adaptation can be achieved easily with most feed-forward network models by extending them with LMMD loss, which can be trained efficiently via back-propagation. Experiments demonstrate that DSAN can achieve remarkable results on both object recognition tasks and digit classification tasks. Our code will be available at: https://github.com/easezyc/deep-transfer-learning.
|
|
|
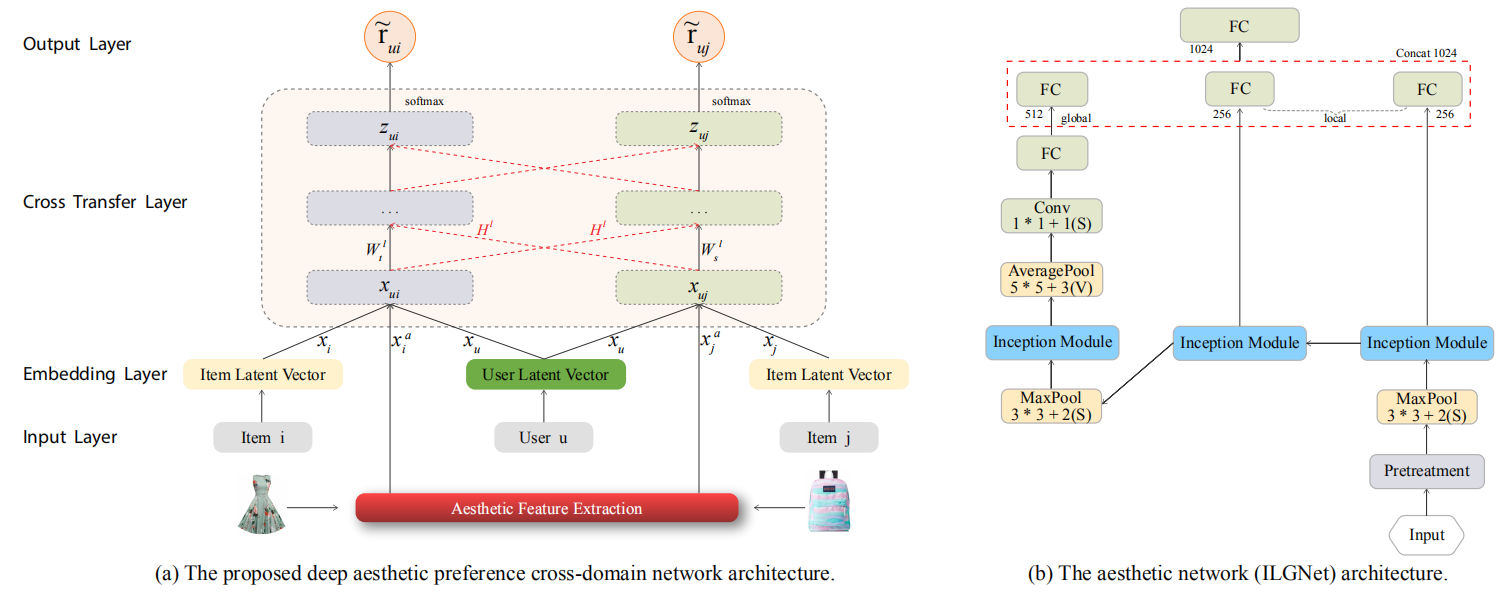
Pengpeng Zhao, Fuzhen Zhuang, Yanchi Liu, Victor S. Sheng, Jiajie Xu, Xiaofang Zhou and Hui Xiong: Exploiting Aesthetic Preference in Deep Cross Networks for Cross-domain Recommendation. TheWebConf 2020.
Visual aesthetics of products plays an important role in the decision
process when purchasing appearance-first products, e.g., clothes.
Indeed, user’s aesthetic preference, which serves as a personality
trait and a basic requirement, is domain independent and could be
used as a bridge between domains for knowledge transfer. However,
existing work has rarely considered the aesthetic information in
product images for cross-domain recommendation. To this end, in
this paper, we propose a new deep Aesthetic Cross-Domain Networks (ACDN), in which parameters characterizing personal aesthetic preferences are shared across networks to transfer knowledge
between domains. Specifically, we first leverage an aesthetic network to extract aesthetic features. Then, we integrate these features
into a cross-domain network to transfer users’ domain independent aesthetic preferences. Moreover, network cross-connections
are introduced to enable dual knowledge transfer across domains.
Finally, the experimental results on real-world datasets show that
our proposed model ACDN outperforms benchmark methods in
terms of recommendation accuracy.
|
|
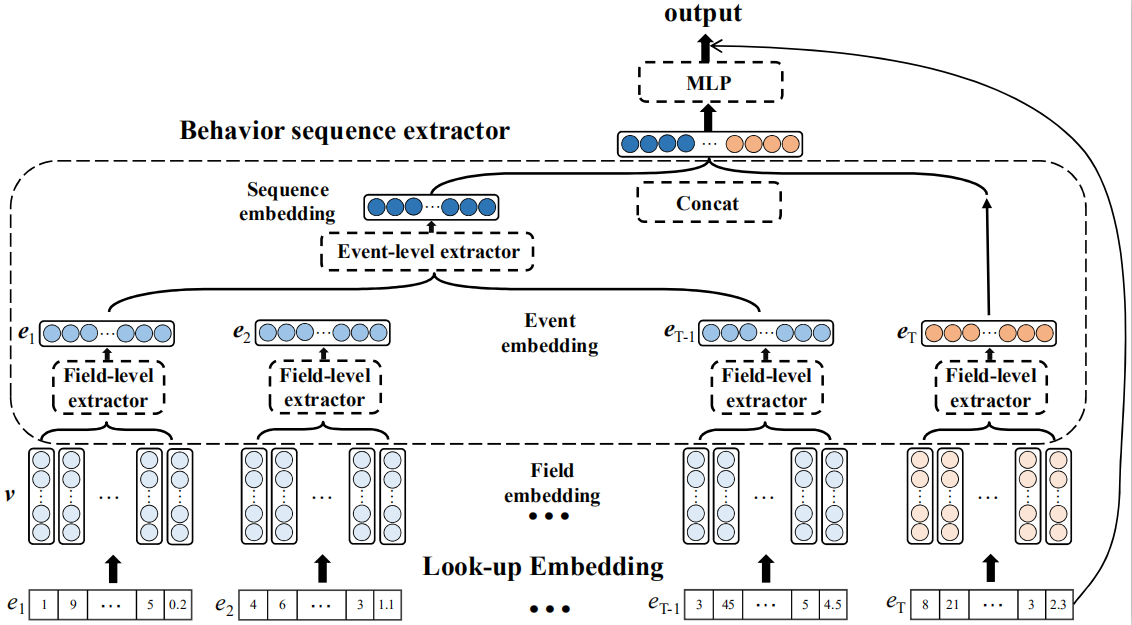
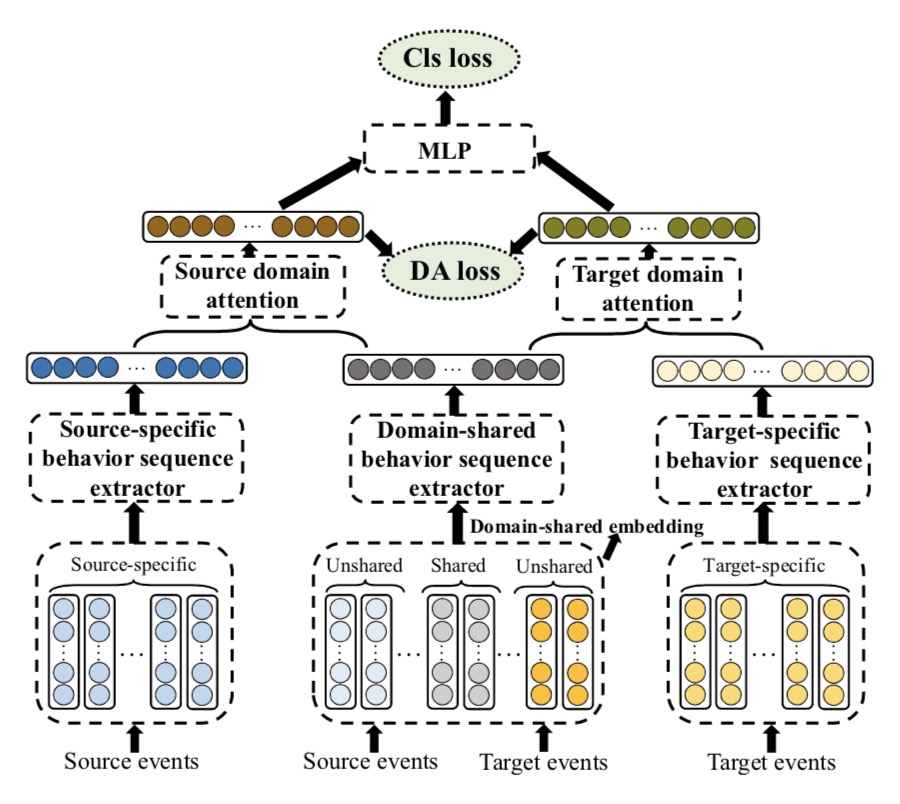
Yongchun Zhu, Dongbo Xi, Bowen Song, Fuzhen Zhuang*, Shuai Chen, Xi Gu and Qing He: Modeling Users’ Behavior Sequences with Hierarchical Explainable Network for Cross-domain Fraud Detection. TheWebConf 2020.
With the explosive growth of the e-commerce industry, detectingonline transaction fraud in real-world applications has become increasingly important to the development of e-commerce platforms. The sequential behavior history of users provides useful information in differentiating fraudulent payments from regular ones. Recently, some approaches have been proposed to solve this sequence-based fraud detection problem. However, these methods usually suffer from two problems: the prediction results are difficult to explain and the exploitation of the internal information of behaviors is insufficient. To tackle the above two problems, we propose a Hierarchical Explainable Network (HEN) to model users’ behavior sequences, which could not only improve the performance of fraud detection but also make the inference process interpretable.
Meanwhile, as e-commerce business expands to new domains, e.g., new countries or new markets, one major problem for modeling user behavior in fraud detection systems is the limitation of data collection, e.g., very few data/labels available. Thus, in this paper, we further propose a transfer framework to tackle the cross-domain fraud detection problem, which aims to transfer knowledge from existing domains (source domains) with enough and mature data to improve the performance in the new domain (target domain). Our proposed method is a general transfer framework that could not only be applied upon HEN but also various existing models in the Embedding & MLP paradigm.
By utilizing data from a world-leading cross-border e-commerce platform, we conduct extensive experiments in detecting card-stolen transaction frauds in different countries to demonstrate the superior performance of HEN. Besides, based on 90 transfer task experiments, we also demonstrate that our transfer framework could not only con?tribute to the cross-domain fraud detection task with HEN, but also be universal and expandable for various existing models. Moreover, HEN and the transfer framework form three-level attention which greatly increases the explainability of the detection results.
|
|
|
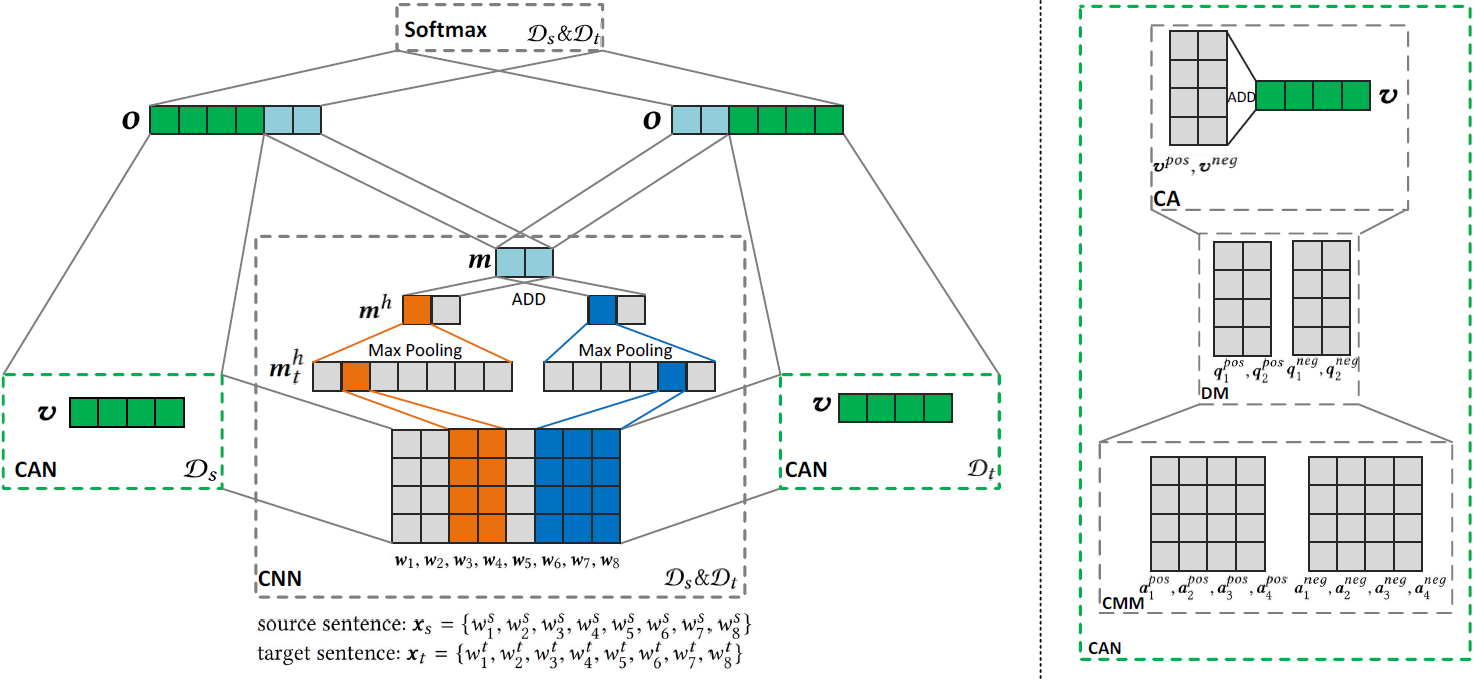
Dongbo Xi, Fuzhen Zhuang*, Ganbin Zhou, Xiaohu Cheng, Fen Lin and Qing He: Domain Adaptation with Category Attention Network for Deep Sentiment Analysis. TheWebConf 2020.
-
Domain adaptation tasks such as cross-domain sentiment classification aim to utilize existing labeled data in the source domain and unlabeled or few labeled data in the target domain to improve the performance in the target domain via reducing the shift between the data distributions. Existing cross-domain sentiment classification methods need to distinguish pivots, i.e., the domain-shared sentiment words, and non-pivots, i.e., the domain-specific sentiment words, for excellent adaptation performance.
In this paper, we first design a Category Attention Network (CAN), and then propose a model named CAN-CNN to integrate CAN and a Convolutional Neural Network (CNN). On the one hand, the model regards pivots and non-pivots as unified category attribute words and can automatically capture them to improve the domain adaptation performance; on the other hand, the model makes an attempt at interpretability to learn the transferred category attribute words. Specifically, the optimization objective of our model has three different components: 1) the supervised classification loss; 2) the distributions loss of category feature weights; 3) the domain invariance loss.
Finally, the proposed model is evaluated on three public sentiment analysis datasets and the results demonstrate that CAN-CNN can outperform other various baseline methods.
|
 |
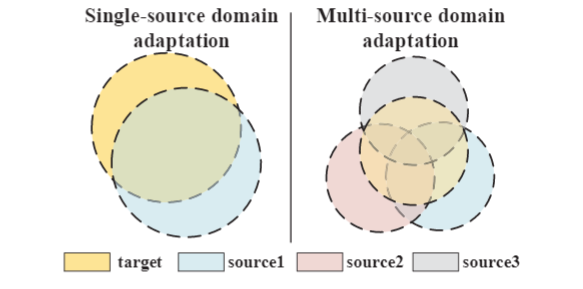
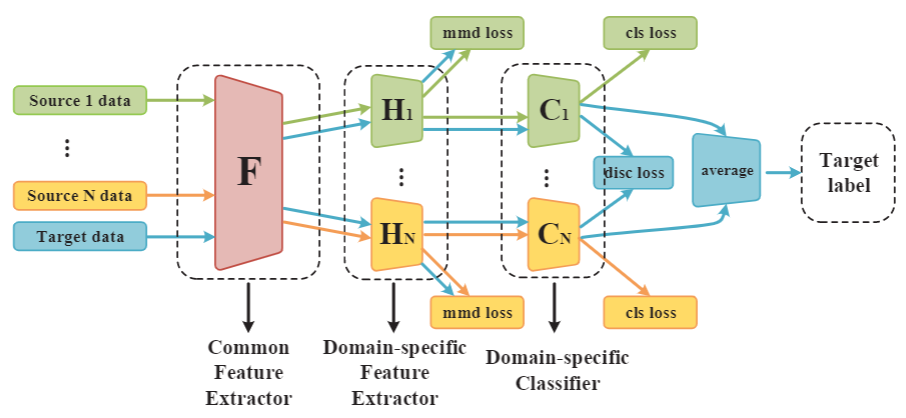
Yongchun Zhu, Fuzhen Zhuang*, Deqing Wang: Aligning Domain-specific Distribution and Classifier for Cross-domain Classification from Multiple Sources. AAAI 2019.
-
While Unsupervised Domain Adaptation (UDA) algorithms, i.e., there are only labeled data from source domains, have been actively studied in recent years, most algorithms and theoretical results focus on Single-source Unsupervised Domain Adaptation (SUDA). However, in the practical scenario, labeled data can be typically collected from multiple diverse sources, and they might be different not only from the target domain but also from each other. Thus, domain adapters from multiple sources should not be modeled in the same way. Recent deep learning based Multi-source Unsupervised Domain Adaptation (MUDA) algorithms focus on extracting common domain-invariant representations for all domains by aligning distribution of all pairs of source and target domains in a common feature space. However, it is often very hard to extract the same domain-invariant representations for all domains in MUDA. In addition, these methods match distributions without considering domain-specific decision boundaries between classes. To solve these problems, we propose a new framework with two alignment stages for MUDA which not only respectively aligns the distributions of each pair of source and target domains in multiple specific feature spaces, but also aligns the outputs of classifiers by utilizing the domain-specific decision boundaries. Extensive experiments demonstrate that our method can achieve remarkable results on popular benchmark datasets for image classification.
|
 |
 |
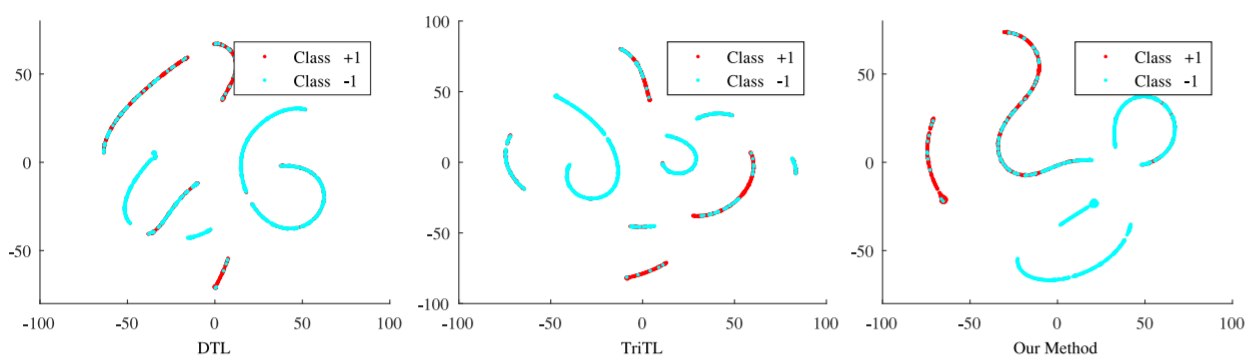
Deqing Wang, Chenwei Lu, Junjie Wu, Hongfu Liu, Wenjie Zhang, Fuzhen Zhuang, Hui Zhang: Softly Associative Transfer Learning for Cross-Domain Classification. IEEE Transactions on Cybernetics, 2019.
-
The main challenge of cross-domain text classification is to train a classifier in a source domain while applying
it to a different target domain. Many transfer learning-based
algorithms, for example, dual transfer learning, triplex transfer
learning, etc., have been proposed for cross-domain classification,
by detecting a shared low-dimensional feature representation for
both source and target domains. These methods, however, often
assume that the word clusters matrix or the clusters association matrix as knowledge transferring bridges are exactly the
same across different domains, which is actually unrealistic in
real-world applications and, therefore, could degrade classification performance. In light of this, in this paper, we propose a
softly associative transfer learning algorithm for cross-domain
text classification. Specifically, we integrate two non-negative
matrix tri-factorizations into a joint optimization framework,
with approximate constraints on both word clusters matrices
and clusters association matrices so as to allow proper diversity
in knowledge transfer, and with another approximate constraint
on class labels in source domains in order to handle noisy labels.
An iterative algorithm is then proposed to solve the above problem, with its convergence verified theoretically and empirically.
Extensive experimental results on various text datasets demonstrate the effectiveness of our algorithm, even with the presence
of abundant state-of-the-art competitors.
|
 |
Fuzhen Zhuang , Xiaohu Cheng , Ping Luo , Sinno Jialin Pan , Qing He: Supervised Representation Learning with Double Encoding-Layer Autoencoder for Transfer Learning. ACM TIST 2018.
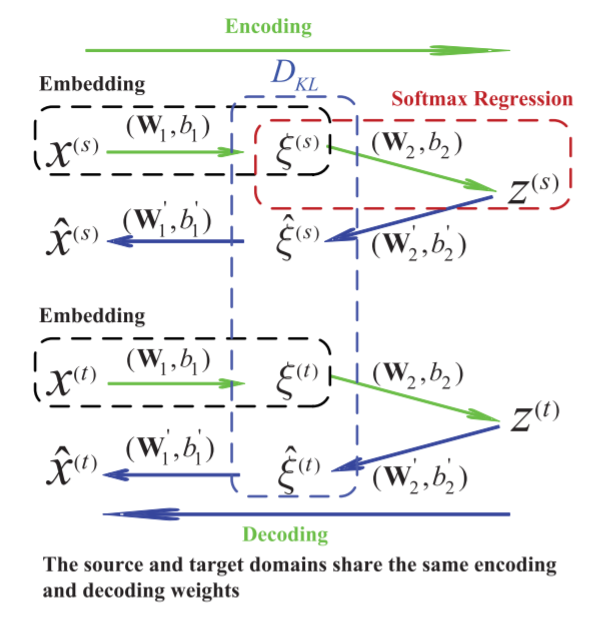 |
-
Transfer learning has gained a lot of attention and interest in the past decade. One crucial research issue
in transfer learning is how to find a good representation for instances of different domains such that the
divergence between domains can be reduced with the new representation. Recently, deep learning has been
proposed to learn more robust or higher-level features for transfer learning. In this article, we adapt the autoencoder technique to transfer learning and propose a supervised representation learning method based
on double encoding-layer autoencoder. The proposed framework consists of two encoding layers: one for
embedding and the other one for label encoding. In the embedding layer, the distribution distance of the
embedded instances between the source and target domains is minimized in terms of KL-Divergence. In the
label encoding layer, label information of the source domain is encoded using a softmax regression model.
Moreover, to empirically explore why the proposed framework can work well for transfer learning, we propose a new effective measure based on autoencoder to compute the distribution distance between different
domains. Experimental results show that the proposed new measure can better reflect the degree of transfer
difficulty and has stronger correlation with the performance from supervised learning algorithms (e.g., Logistic Regression), compared with previous ones, such as KL-Divergence and Maximum Mean Discrepancy.
Therefore, in our model, we have incorporated two distribution distance measures to minimize the difference
between source and target domains in the embedding representations. Extensive experiments conducted on
three real-world image datasets and one text data demonstrate the effectiveness of our proposed method
compared with several state-of-the-art baseline methods.
|
Baoyu Jing, Chenwei Lu ,Deqing Wang , Fuzhen Zhuang, Cheng Niu: Cross-Domain Labeled LDA for Cross-Domain Text Classification. ICDM 2018.
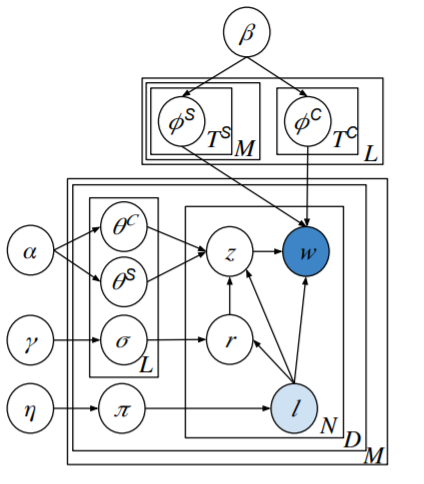 |
-
Cross-domain text classification aims at building
a classifier for a target domain which leverages data from
both source and target domain. One promising idea is to
minimize the feature distribution differences of the two domains.
Most existing studies explicitly minimize such differences by
an exact alignment mechanism (aligning features by one-to-one
feature alignment, projection matrix etc.). Such exact alignment,
however, will restrict models’ learning ability and will further
impair models’ performance on classification tasks when the
semantic distributions of different domains are very different.
To address this problem, we propose a novel group alignment
which aligns the semantics at group level. In addition, to help
the model learn better semantic groups and semantics within
these groups, we also propose a partial supervision for model’s
learning in source domain. To this end, we embed the group
alignment and a partial supervision into a cross-domain topic
model, and propose a Cross-Domain Labeled LDA (CDL-LDA).
On the standard 20Newsgroup and Reuters dataset, extensive
quantitative (classification, perplexity etc.) and qualitative (topic
detection) experiments are conducted to show the effectiveness
of the proposed group alignment and partial supervision.
|
Jia He , Rui Liu , Fuzhen Zhuang* , Fen Lin , Cheng Niu , Qing He : A General Cross-Domain Recommendation Framework via Bayesian Neural Network. ICDM 2018.
-
Collaborative filtering is an effective and widely
used recommendation approach by applying the user-item rating
matrix for recommendations, however, which usually suffers from
cold-start and sparsity problems. To address these problems,
hybrid methods are proposed to incorporate auxiliary information such as user/item profiles to collaborative filtering models;
Cross-domain recommendation systems add a new dimension
to solve these problems by leveraging ratings from other domains to improve recommendation performance. Among these
methods, deep neural network based recommendation systems
achieve excellent performance due to their excellent ability in
learning powerful representations. However, these cross-domain
recommendation systems based on deep neural network rarely
consider the uncertainty of weights. Therefore, they maybe lack
of calibrated probabilistic predictions and make overly confident
decisions. Along this line, we propose a general cross-domain
recommendation framework via Bayesian neural network to
incorporate auxiliary information, which takes advantage of
both the hybrid recommendation methods and the cross-domain
recommendation systems. Specifically, our framework consists of
two kinds of neural networks, one to learn the low dimensional
representation from the one-hot codings of users/items, while the
other one is to project the auxiliary information of users/items
into another latent space. The final rating is produced by
integrating the latent representations of the one-hot codings of
users/items and the auxiliary information of users/items. The
latent representations of users learnt from ratings and auxiliary
information are shared across different domains for knowledge
transfer. Moreover, we capture the uncertainty in all weights
by representing weights with Gaussian distributions to make
calibrated probabilistic predictions. We have done extensive
experiments on real-world data sets to verify the effectiveness
of our framework.
|
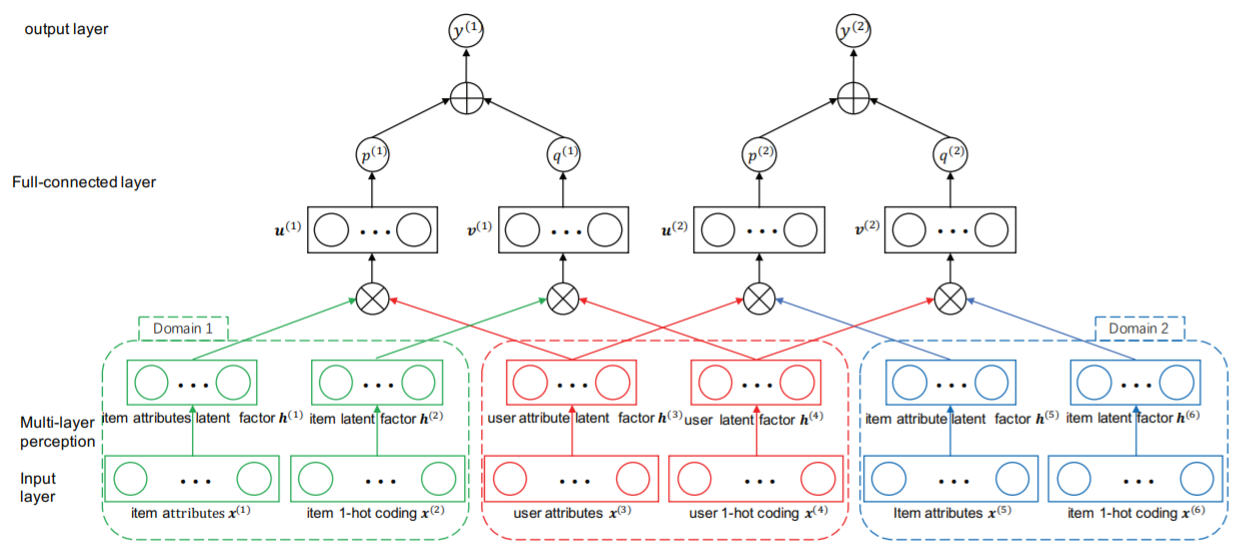 |
Fuzhen Zhuang , Yingmin Zhou , Fuzheng Zhang , Xiang Ao , Xing Xie , Qing He : Sequential Transfer Learning: Cross-domain Novelty Seeking Trait Mining for Recommendation. WWW (Companion Volume) 2017.
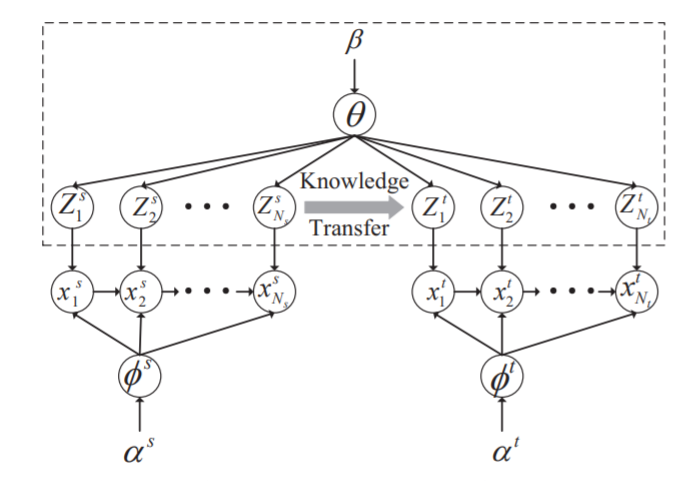 |
-
Recent studies in psychology suggest that novelty-seeking trait is
highly related to consumer behavior, which has a profound business
impact on online recommendation. This paper studies the problem
of mining novelty seeking trait across domains to improve the recommendation performance in target domain. We propose an efficient model, CDNST, which significantly improves the recommendation performance by transferring the knowledge from auxiliary
source domain. We conduct extensive experiments on three domain
datasets crawled from Douban (www.douban.com) to demonstrate
the effectiveness of the proposed model. Moreover, we find that the
property of sequential data affects the performance of CDNST.
|
Fuzhen Zhuang, Ping Luo, Sinno Jialin Pan, Hui Xiong, Qing He: Ensemble of Anchor Adapters for Transfer Learning. CIKM 2016.
-
In the past decade, there have been a large number of transfer
learning algorithms proposed for various real-world applications.
However, most of them are vulnerable to negative transfer1
since
their performance is even worse than traditional supervised models. Aiming at more robust transfer learning models, we propose an
ENsemble framework of anCHOR adapters (ENCHOR for short),
in which an anchor adapter adapts the features of instances based
on their similarities to a specif c anchor (i.e., a selected instance).
Specif cally, the more similar to the anchor instance, the higher degree of the original feature of an instance remains unchanged in the
adapted representation, and vice versa. This adapted representation
for the data actually expresses the local structure around the corresponding anchor, and then any transfer learning method can be applied to this adapted representation for a prediction model, which
focuses more on the neighborhood of the anchor. Next, based on
multiple anchors, multiple anchor adapters can be built and combined into an ensemble for f nal output. Additionally, we develop
an effective measure to select the anchors for ensemble building to
achieve further performance improvement. Extensive experiments
on hundreds of text classif cation tasks are conducted to demonstrate the effectiveness of ENCHOR. The results show that: when
traditional supervised models perform poorly, ENCHOR (based on
only 8 selected anchors) achieves 6% − 13% increase in terms of
average accuracy compared with the state-of-the-art methods, and
it greatly alleviates negative transfer.
|
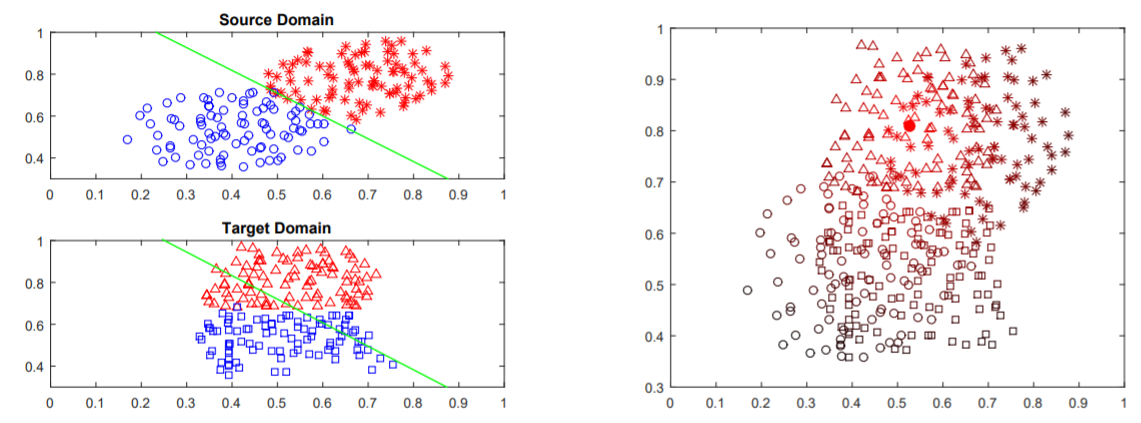 |
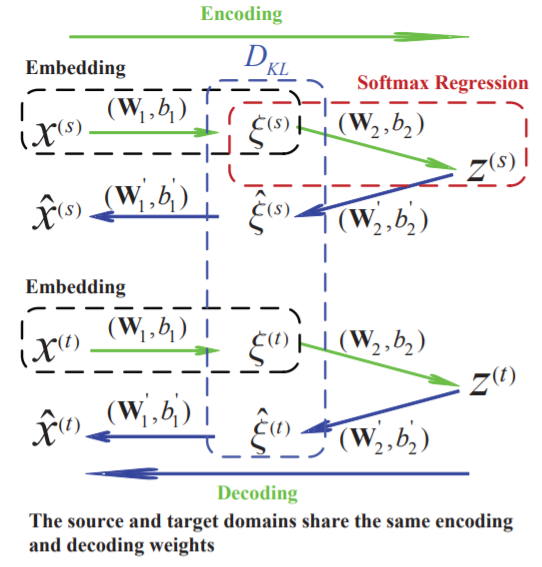
Fuzhen Zhuang, Xiaohu Cheng, Ping Luo, Sinno Jialin Pan, Qing He: Supervised Representation Learning: Transfer Learning with Deep Autoencoders. IJCAI 2015.
 |
-
Transfer learning has attracted a lot of attention
in the past decade. One crucial research issue in
transfer learning is how to find a good representation for instances of different domains such that the
divergence between domains can be reduced with
the new representation. Recently, deep learning
has been proposed to learn more robust or higherlevel features for transfer learning. However, to the
best of our knowledge, most of the previous approaches neither minimize the difference between
domains explicitly nor encode label information in
learning the representation. In this paper, we propose a supervised representation learning method
based on deep autoencoders for transfer learning.
The proposed deep autoencoder consists of two
encoding layers: an embedding layer and a label
encoding layer. In the embedding layer, the distance in distributions of the embedded instances between the source and target domains is minimized
in terms of KL-Divergence. In the label encoding
layer, label information of the source domain is encoded using a softmax regression model. Extensive
experiments conducted on three real-world image
datasets demonstrate the effectiveness of our proposed method compared with several state-of-theart baseline methods.
|
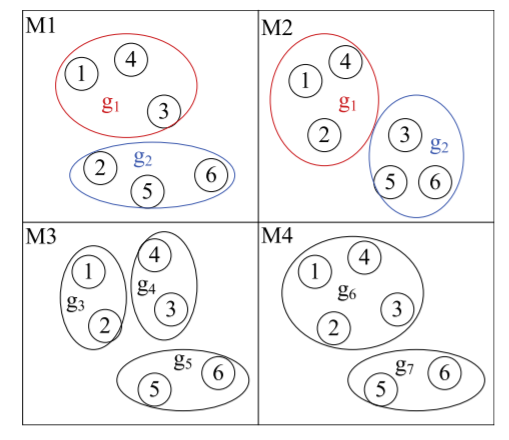
Xiang Ao, Ping Luo, Xudong Ma, Fuzhen Zhuang, Qing He, Zhongzhi Shi, Zhiyong Shen: Combining supervised and unsupervised models via unconstrained probabilistic embedding. Inf. Sci. 257 : 101-114 (2014).
 |
-
In this study, we consider an ensemble problem in which we combine outputs coming from
models developed in the supervised and unsupervised modes. By jointly considering the
grouping results coming from unsupervised models we aim to improve the classification
accuracy of supervised model ensemble. Here, we formulate the ensemble task as an
Unconstrained Probabilistic Embedding (UPE) problem. Specifically, we assume both objects
and classes/clusters have latent coordinates without constraints in a D-dimensional Euclidean space, and consider the mapping from the embedded space into the space of model
results as a probabilistic generative process. A solution to this embedding can be obtained
using the quasi-Newton method, which makes objects and classes/clusters with high cooccurrence weights are embedded close. Then, prediction is determined by taking the distances between the object and the classes in the embedded space. We demonstrate the
benefits of this unconstrained embedding method by running extensive and systematic
experiments on real-world datasets. Furthermore, we conduct experiments to investigate
how the quality and the number of clustering models affect the performance of this ensemble method. We also show the robustness of the proposed model.
|
Fuzhen Zhuang, Xiaohu Cheng, Sinno Jialin Pan, Wenchao Yu, Qing He, Zhongzhi Shi: Transfer Learning with Multiple Sources via Consensus Regularized Autoencoders. ECML/PKDD 2014
-
Knowledge transfer from multiple source domains to a target domain
is crucial in transfer learning. Most existing methods are focused on learning
weights for different domains based on the similarities between each source domain and the target domain or learning more precise classifiers from the source
domain data jointly by maximizing their consensus of predictions on the target
domain data. However, these methods only consider measuring similarities or
building classifiers on the original data space, and fail to discover a more powerful feature representation of the data when transferring knowledge from multiple
source domains to the target domain. In this paper, we propose a new framework
for transfer learning with multiple source domains. Specifically, in the proposed
framework, we adopt autoencoders to construct a feature mapping from an original instance to a hidden representation, and train multiple classifiers from the
source domain data jointly by performing an entropy-based consensus regularizer on the predictions on the target domain. Based on the framework, a particular
solution is proposed to learn the hidden representation and classifiers simultaneously. Experimental results on image and text real-world datasets demonstrate the
effectiveness of our proposed method compared with state-of-the-art methods.
|
 |
Fuzhen Zhuang, Ping Luo, Peifeng Yin, Qing He, Zhongzhi Shi: Concept Learning for Cross-domain Text Classification: a General Probabilistic Framework. IJCAI 2013.
-
Cross-domain learning targets at leveraging the
knowledge from source domains to train accurate
models for the test data from target domains with
different but related data distributions. To tackle the
challenge of data distribution difference in terms
of raw features, previous works proposed to mine
high-level concepts (e.g., word clusters) across data
domains, which shows to be more appropriate for
classification. However, all these works assume
that the same set of concepts are shared in the
source and target domains in spite that some distinct concepts may exist only in one of the data domains. Thus, we need a general framework, which
can incorporate both shared and distinct concepts,
for cross-domain classification. To this end, we
develop a probabilistic model, by which both the
shared and distinct concepts can be learned by the
EM process which optimizes the data likelihood.
To validate the effectiveness of this model we intentionally construct the classification tasks where
the distinct concepts exist in the data domains. The
systematic experiments demonstrate the superiority of our model over all compared baselines, especially on those much more challenging tasks.
|
 |
Fuzhen Zhuang, Ping Luo, Zhiyong Shen, Qing He, Yuhong Xiong, Zhongzhi Shi, Hui Xiong. Mining Distinction and Commonality across Multiple Domains using Generative Model for Text Classification. IEEE TKDE 2012.
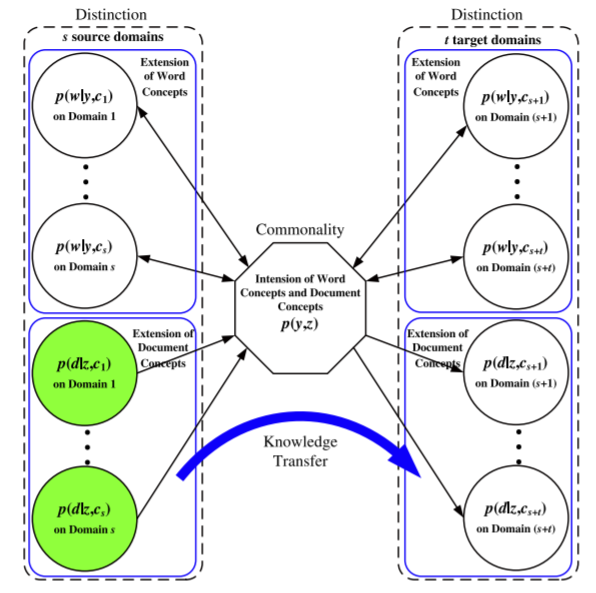 |
-
The distribution difference among multiple domains has been exploited for cross-domain text categorization in recent
years. Along this line, we show two new observations in this study. First, the data distribution difference is often due to the fact that
different domains use different index words to express the same concept. Second, the association between the conceptual feature and
the document class can be stable across domains. These two observations actually indicate the distinction and commonality across
domains. Inspired by the above observations, we propose a generative statistical model, named Collaborative Dual-PLSA (CD-PLSA),
to simultaneously capture both the domain distinction and commonality among multiple domains. Different from Probabilistic Latent
Semantic Analysis (PLSA) with only one latent variable, the proposed model has two latent factors y and z, corresponding to word
concept and document class, respectively. The shared commonality intertwines with the distinctions over multiple domains, and is also
used as the bridge for knowledge transformation. An Expectation Maximization (EM) algorithm is developed to solve the CD-PLSA
model, and further its distributed version is exploited to avoid uploading all the raw data to a centralized location and help to mitigate
privacy concerns. After the training phase with all the data from multiple domains we propose to refine the immediate outputs using
only the corresponding local data. In summary, we propose a two-phase method for cross-domain text classification, the first phase for
collaborative training with all the data, and the second step for local refinement. Finally, we conduct extensive experiments over
hundreds of classification tasks with multiple source domains and multiple target domains to validate the superiority of the proposed
method over existing state-of-the-art methods of supervised and transfer learning. It is noted to mention that as shown by the
experimental results CD-PLSA for the collaborative training is more tolerant of distribution differences, and the local refinement also
gains significant improvement in terms of classification accuracy.
|
Xudong Ma, Ping Luo, Fuzhen Zhuang, Qing He, Zhongzhi Shi, Zhiyong Shen. Combining Su- pervised and Unsupervised Models via Unconstrained Probabilistic Embedding. IJCAI 2011.
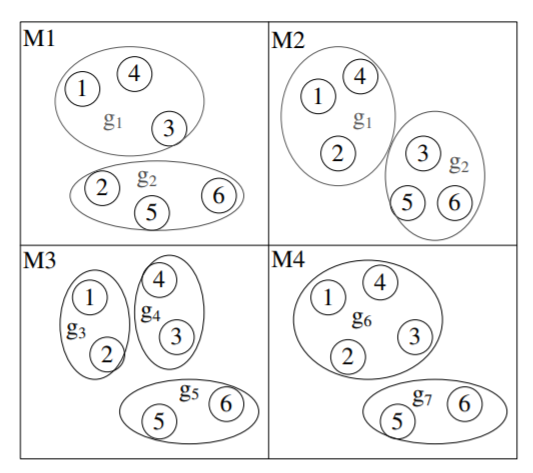 |
-
Ensemble learning with output from multiple supervised and unsupervised models aims to improve
the classification accuracy of supervised model ensemble by jointly considering the grouping results
from unsupervised models. In this paper we cast
this ensemble task as an unconstrained probabilistic embedding problem. Specifically, we assume
both objects and classes/clusters have latent coordinates without constraints in a D-dimensional Euclidean space, and consider the mapping from the
embedded space into the space of results from supervised and unsupervised models as a probabilistic generative process. The prediction of an object
is then determined by the distances between the object and the classes in the embedded space. A solution of this embedding can be obtained using the
quasi-Newton method, resulting in the objects and
classes/clusters with high co-occurrence weights
being embedded close. We demonstrate the benefits of this unconstrained embedding method by
three real applications.
|
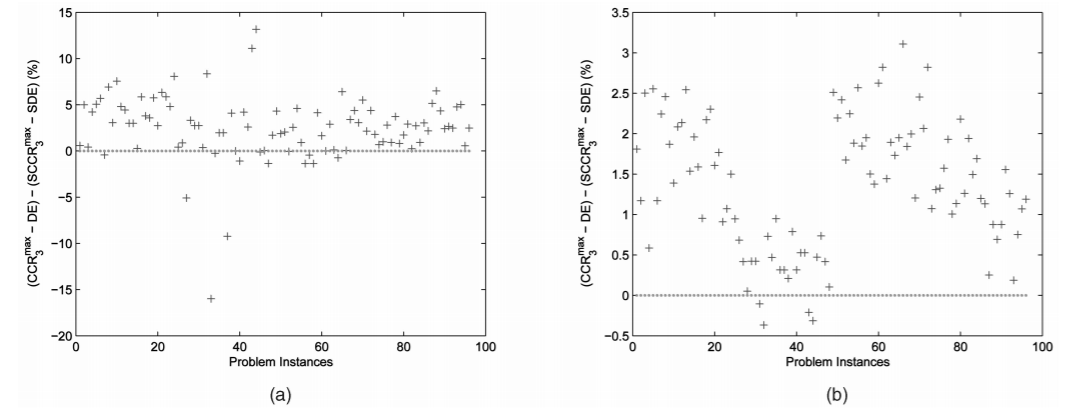
Fuzhen Zhuang, Ping Luo, Hui Xiong, Yuhong Xiong, Qing He, Zhongzhi Shi. Cross-domain Learning From Multiple Sources: A Consensus Regularization Perspective. IEEE TKDE, 2010.
-
Classification across different domains studies how to adapt a learning model from one domain to another domain which shares similar data characteristics. While there are a number of existing works along this line, many of them are only focused on learning from a single source domain to a target domain. In particular, a remaining challenge is how to apply the knowledge learned from multiple source domains to a target domain. Indeed, data from multiple source domains can be semantically related, but have different data distributions. It is not clear how to exploit the distribution differences among multiple source domains to boost the learning performance in a target domain. To that end, in this paper, we propose a consensus regularization framework for learning from multiple source domains to a target domain. In this framework, a local classifier is trained by considering both local data available in one source domain and the prediction consensus with the classifiers learned from other source domains. Moreover, we provide a theoretical analysis as well as an empirical study of the proposed consensus regularization framework. The experimental results on text categorization and image classification problems show the effectiveness of this consensus regularization learning method. Finally, to deal with the situation that the multiple source domains are geographically distributed, we also develop the distributed version of the proposed algorithm, which avoids the need to upload all the data to a centralized location and helps to mitigate privacy concerns.
|
 |
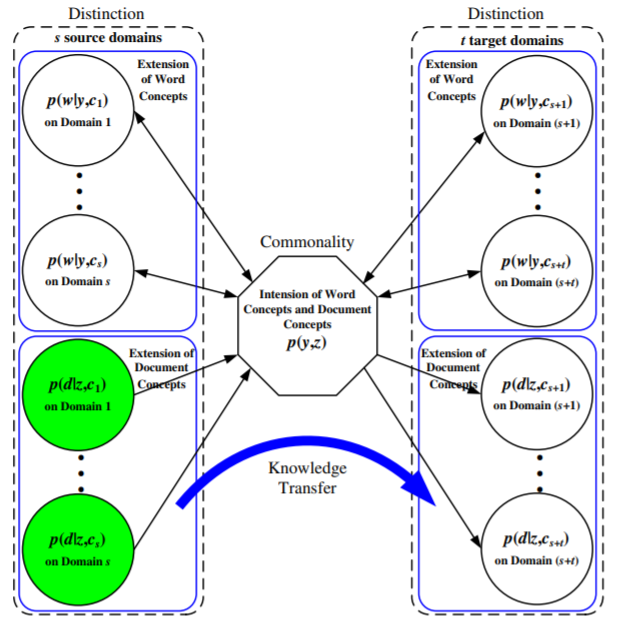
Fuzhen Zhuang, Ping Luo, Zhiyong Shen, Qing He, Yuhong Xiong, Zhongzhi Shi, Hui Xiong. Collaborative Dual-PLSA: Mining Distinction and Commonality across Multiple Domains for Text Classification. CIKM 2010.
 |
-
The distribution difference among multiple data domains
has been considered for the cross-domain text classification
problem. In this study, we show two new observations along
this line. First, the data distribution difference may come
from the fact that different domains use different key words
to express the same concept. Second, the association between this conceptual feature and the document class may
be stable across domains. These two issues are actually the
distinction and commonality across data domains.
Inspired by the above observations, we propose a generative statistical model, named Collaborative Dual-PLSA
(CD-PLSA), to simultaneously capture both the domain distinction and commonality among multiple domains. Different from Probabilistic Latent Semantic Analysis (PLSA)
with only one latent variable, the proposed model has two
latent factors y and z, corresponding to word concept and
document class respectively. The shared commonality intertwines with the distinctions over multiple domains, and
is also used as the bridge for knowledge transformation.
We exploit an Expectation Maximization (EM) algorithm
to learn this model, and also propose its distributed version to handle the situation where the data domains are
geographically separated from each other. Finally, we conduct extensive experiments over hundreds of classification
tasks with multiple source domains and multiple target domains to validate the superiority of the proposed CD-PLSA
model over existing state-of-the-art methods of supervised
and transfer learning. In particular, we show that CD-PLSA
is more tolerant of distribution differences.
|
Fuzhen Zhuang, Ping Luo, Hui Xiong, Qing He, Yuhong Xiong, Zhongzhi Shi. Exploiting Asso- ciations between Word Clusters and Document Classes for Cross-domain Text Categorization. SDM 2010.
-
Cross-domain text categorization targets on adapting the
knowledge learnt from a labeled source-domain to an unlabeled target-domain, where the documents from the source
and target domains are drawn from different distributions.
However, in spite of the different distributions in raw word
features, the associations between word clusters (conceptual
features) and document classes may remain stable across different domains. In this paper, we exploit these unchanged
associations as the bridge of knowledge transformation from
the source domain to the target domain by the nonnegative
matrix tri-factorization. Specifically, we formulate a joint
optimization framework of the two matrix tri-factorizations
for the source and target domain data respectively, in which
the associations between word clusters and document classes
are shared between them. Then, we give an iterative algorithm for this optimization and theoretically show its convergence. The comprehensive experiments show the effectiveness of this method. In particular, we show that the proposed method can deal with some difficult scenarios where
baseline methods usually do not perform well.
|
 |
|